
Language
-

Background: When learning a foreign language, it can be difficult to advance beyond the stage of extremely basic competency. Once a person can “kind of” use a language, it is rare that their communication attempts will be corrected by random strangers, so that person will end up saying things like “Here, there is pancakes served?…
-

Background: English lacks sufficiently granular terms for describing the level of friendship between two people: the primary options are just “friend” and “acquaintance.” This is inadequate for representing reality! The Issue: As a common example of where these terms are insufficient, people often have “work friends” or “school friends” (who they wouldn’t specifically seek out…
-

Background: Sometimes, people make references (“literary allusions,” if you prefer) to well-known books, movies, or other shared cultural elements. If the listener recognizes the reference, this can either be a convenient shorthand for describing something: e.g. “it’s a ‘Groundhog Day’ situation“ instead of “it seems like a scenario in which the same occurrence repeats over…
-
Background: Some acronyms already include the “name” of the noun in the acronym: for example, an “ATM” [*] (automatic teller machine) or “PIN” (personal identification number). But for the sake of clarity (and maybe because it sounds more natural in some cases), people will often say “ATM machine” or “PIN number.” [*] Yes, yes, “A.T.M.” is…
-
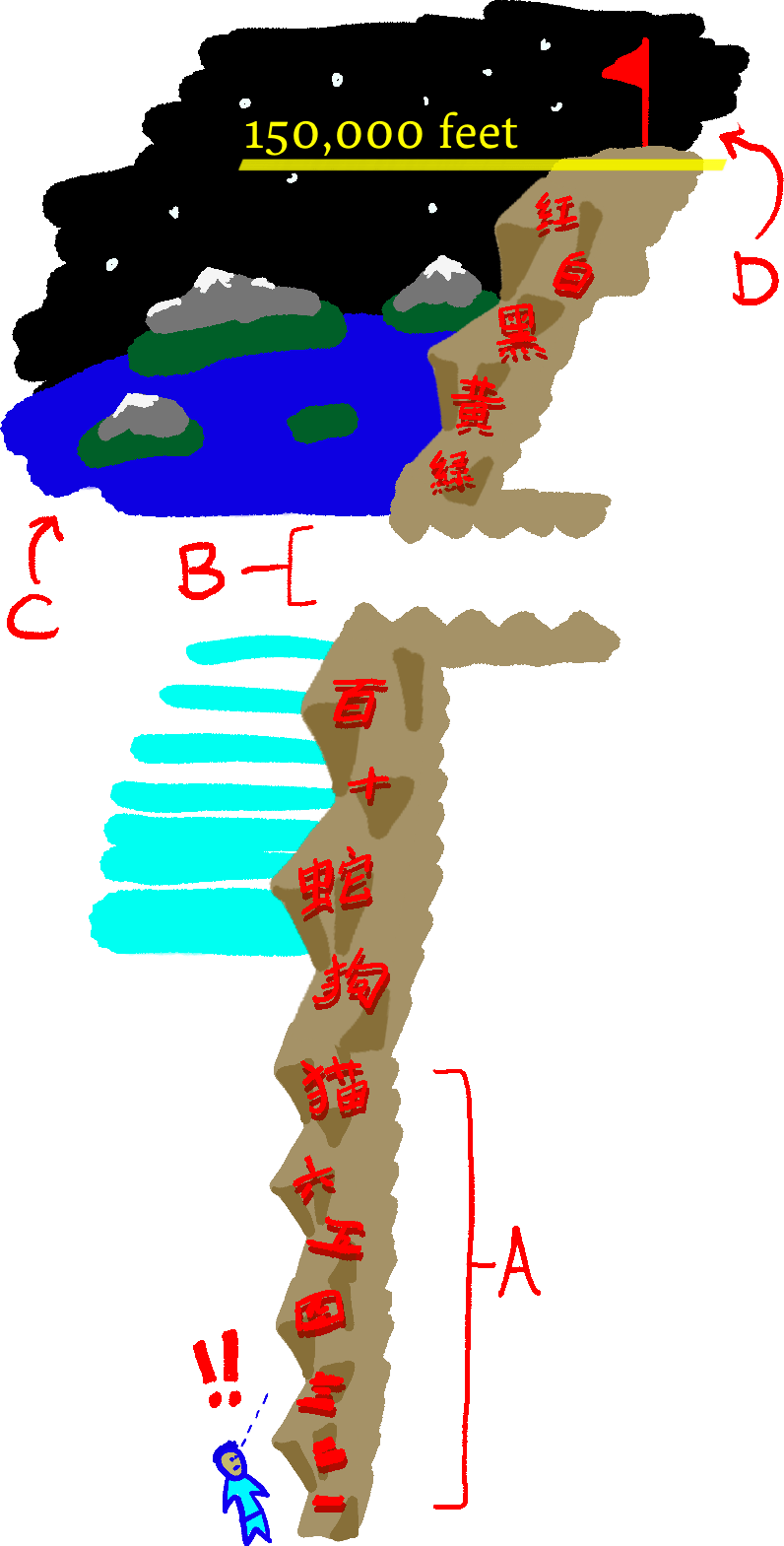
Background: In some climbing gyms, there are introductory climbing walls for children where the climbable hand holds are shaped like a recognizable object (Figure 1), instead of a random-looking piece of stone. Using the 26-letter (capital letters only) English alphabet, we can assemble a reasonably sized climbing wall wall without using any duplicate letters. The…
-

Background: There are a surprisingly huge number of emoji for expressing relatively rarely-used concepts, such as 🎍 (bamboo decoration), 🤾🏻♂️ (handball), 🎠 (carousel horse), 🛖 (thatched-roof cottage), and 🛋️ (couch and lamp). The Issue: Weirdly, there is no “standard” emoji for unambiguously expressing the concept “thanks!” or “you’re welcome!” One commonly seen approximation is 🙏…
-

Background: It has become increasingly difficult for poets to make a living in the modern world. This is probably because all the “good” rhyming words have already been used, leaving modern poets to scavenge for scraps. Fortunately, there are still many English words that are notoriously hard to rhyme: for example, “orange,” “beige,” “walrus,” “circle,”…
-

Background: Learning a foreign language can be time-consuming, primarily due to the large number of words that need to be memorized. Some attempts have been made to make this process easier by making a “common” second language that everyone could learn (the most well-known of these is probably https://en.wikipedia.org/wiki/Esperanto). This would, in theory, fix the…
-
Background: The part of speech known as the “verb”: not strictly necessary! A language without the verb: still technically functional! English vocabulary: already quite large (perhaps excessively large). And obviously fewer words: easier language. Proposal: So for the sake of both children and foreign language students of English, an obvious plan: verbless English! Some examples:…
-
Background: In some languages, there are several variants of words (like “this” or “that”) that give you additional “implicit” information about the world. For example, if a person says “this notebook,” it indicates a notebook that is near them. If they say “that notebook,” it indicates a more distantly-located notebook. Even though a language can…
