
The issue:
Many computers are unable to handle letters that don’t fall into the set of Latin characters used by English.
Even though the Unicode standard has greatly improved multi-character-set accessibility, problems still arise:
- A character might not exist in a chosen font. For example, “Egyptian Hieroglyph of a bird catching a fish” is probably not available in Comic Sans.
- Systems may be unable to cope with characters that look exactly the same (“homoglyphs”: https://en.wikipedia.org/wiki/Homoglyph).
- For example, “Latin A” and “Cyrillic A” look identical, but have different underlying Unicode codes.
- So an email from “YOUR BANK.COM” might actually be from a different site, with an imposter letter “A” (https://en.wikipedia.org/wiki/IDN_homograph_attack).
- (This is an issue in English as well, with 0 (zero) versus O (capital “o”) and “I / l / 1” (capital i, lower-case L, numeral 1).)
- Systems may not allow certain letters for certain situations; for example, if your username is “Linear B ‘stone wheel’ + Mayan jaguar glyph,” it is extremely unlikely that you will have an easy time logging into your user account.
The current failure mode is usually to display a blank rectangle instead, which is unhelpful.
Proposal:
Instead, we can use a sophisticated image-recognition system to map each letter from every language onto one or more Latin characters (Fig. 1).
Usually, this is called transliteration (https://en.wikipedia.org/wiki/Transliteration). But in this case, rather than using the sound of a symbol to convert it, we are using the symbol’s visual appearance, so it’s more like “visual-literation.”

Fig. 1: With a limited character set, it may be easy to display the “Å” as “A”, or “ñ” as “n.” But it’s unclear what should be done with the Chinese character at the bottom, which isn’t similar to any specific Latin letter.
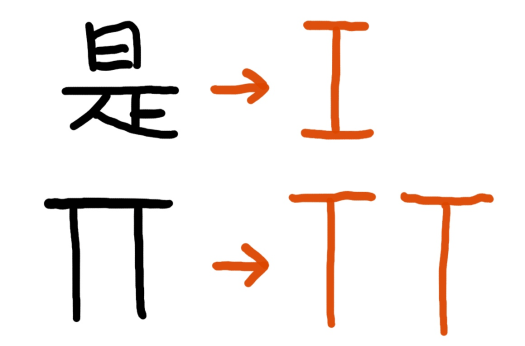
Fig. 2:
Top: Image analysis reveals that the Chinese character (meaning “is”) can be most closely matched to the Latin capital “I.” Bottom: The Greek capital “∏” (pi) is disassembled into two Ts.
Some letters actually do somewhat resemble their Latin-ized versions (like “∏” as “TT”). However, some mappings are slightly less immediately obvious (Fig 3).

Fig. 3: Many complex symbols can—with a great degree of squinting—be matched to multi-letter strings.
Conclusion:
Linguists will love this idea, which forever solves the problem of representing multiple character sets using only the very limited Latin letters.
PROS: Gives every word in every language an unambiguous mapping to a set of (26*2) = 52 Latin letters.
CONS: Many symbols may map to the same end result (for example, “I” could be the English word “I,” or it could have been a “visual-literated” version of “是“).
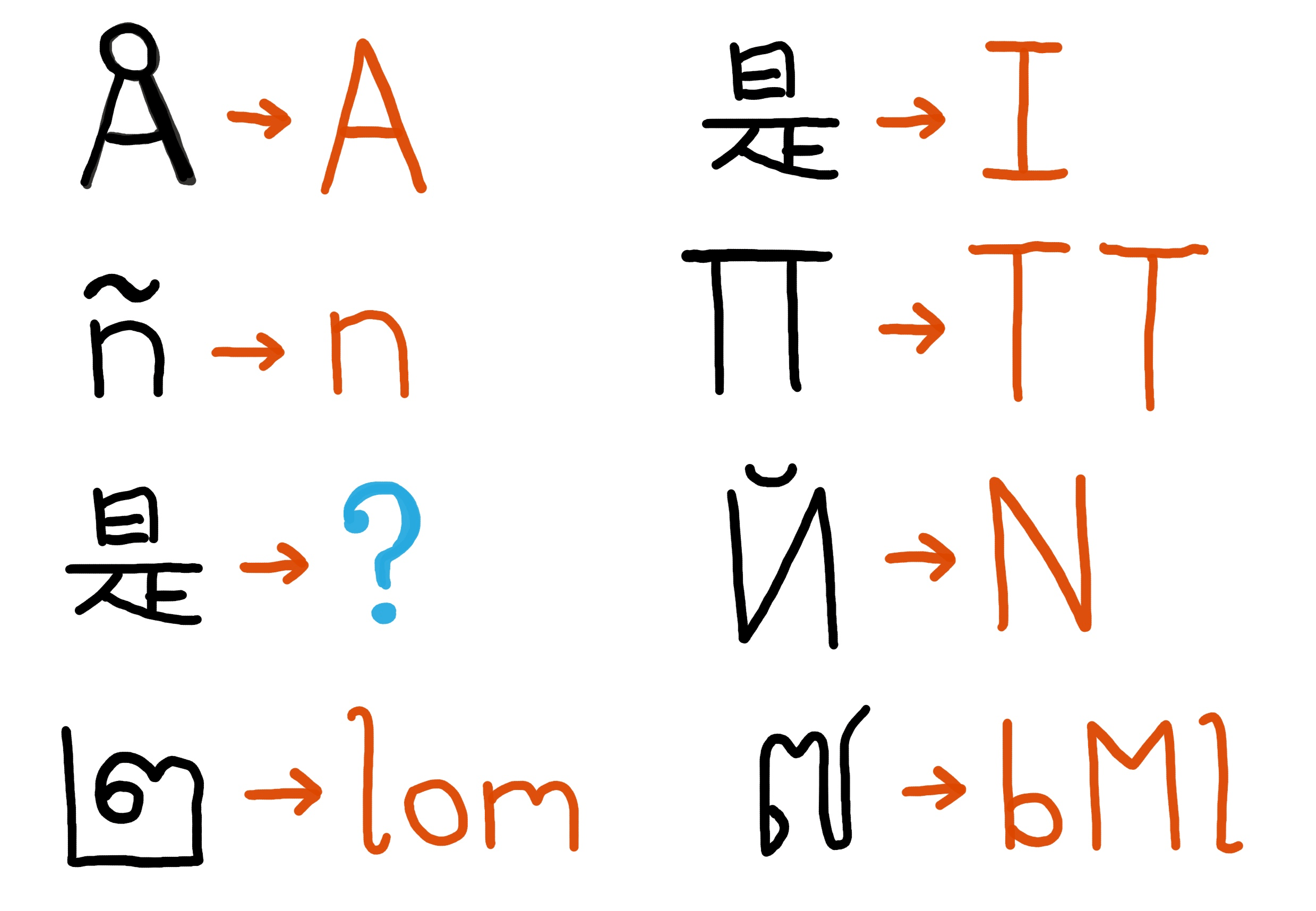
Fig. 4: A collection of potential mappings from various symbols to an ASCII equivalent. Finally, the days of complex transliteration are over!

You must be logged in to post a comment.