
Background:
Security cameras have become extremely cheap, and it’s economically quite feasible for a homeowner to have a really excessive-seeming number covering the entire exterior of their home or apartment.
The Issue:
As more cameras are added, more tiny security camera windows are shown. It can become overwhelming to even try to make sense of them. It should be the case that adding more cameras would improves a surveillance view, but instead it just adds more things to look at.
Proposal:
Imagine that we have a house with three cameras on the roof, positioned as shown in Figure 1.

With current camera-viewing technology, the view from these cameras would be three separate rectangular windows. But what if, instead, we synthesize a 3d model out of them, and have the “live 3d view” shown in Figure 2?
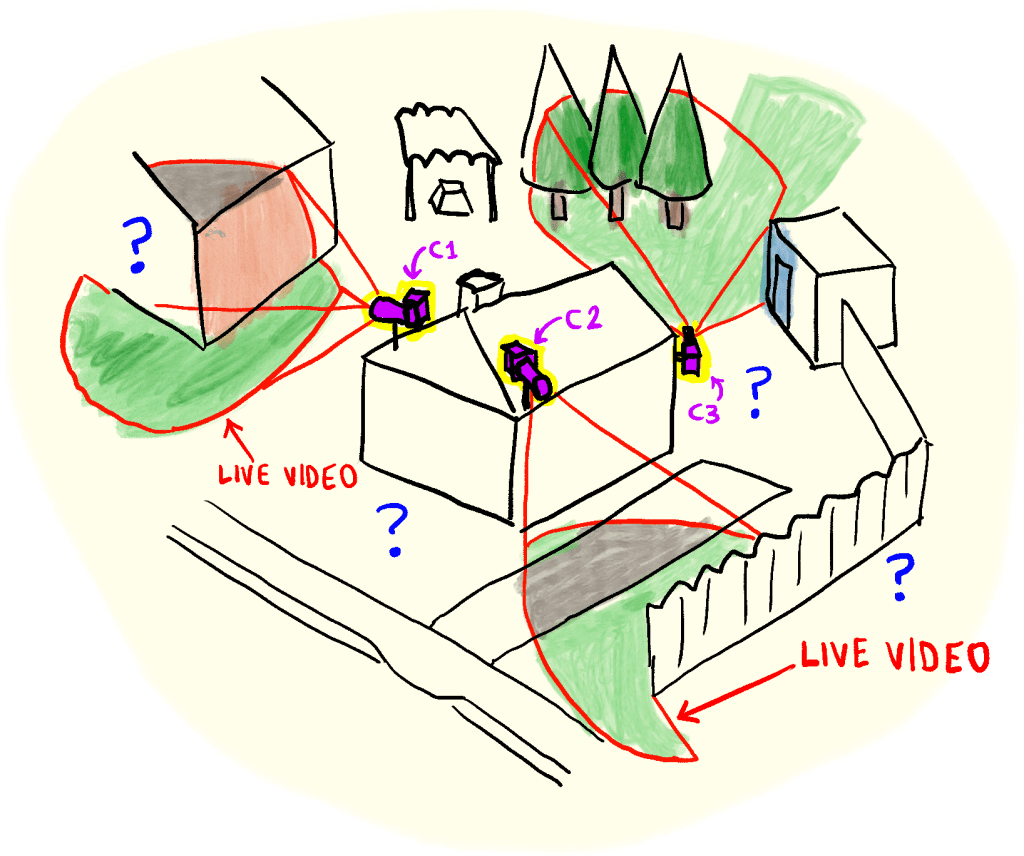
With such a visualization method, the user could rotate their tiny 3d house model around and easily check it for unusual happenings. Adding more cameras would now just increase the resolution of the model, rather than adding more screens to look at.
There are a couple of obvious technical issues:
First, creating the 3d model in the first place might be a bit troublesome. Generally, people won’t want to do this by hand. Perhaps it can be done automatically with LIDAR (which can be used to generate a fairly accurate—at least, to the scale of a few inches—3d model in only a few seconds).
Second, if the 3d model is fixed and unchanging, then we have a problem: suppose a person is walking across the yard: we would want to see them as a three-dimensional object, but they’d actually show up as some weird moving slug-like smear on the existing flat grass (since the person doesn’t have a 3d model). This issue can probably also be solved by LIDAR: the person would show up as a person-shaped three-dimensional blob with a video feed superimposed on it. (A user could always view the “regular” video if they wanted to see details.
Conclusion:
This should hasten the implementation of the 1984-esque dystopian totalitarian nightmare state that we have always dreamed of!
PROS: Might legitimately be a cool way to intuitively monitor a large area. For example, security guards at a large public building could observe a tiny “live diorama” of the building instead of having to somehow maintain their attention on 30 different video feeds.
CONS: Moving objects would probably tend to always be weird 3d blobs. Users might have to always check the video feeds anyway upon seeing motion. It’s also possible that a user might monitor the 3d model feed in such a way that while the camera can see something, the user cannot (imagine there’s someone sneaking on the other side of the fence in the view in Figure 2: the camera can see that person, but the fence blocks our view, unless we rotate the model).

You must be logged in to post a comment.